Yesterday, the President of IQS Research Shawn Herbig spent an hour on the radio discussing some of the intricacies involved […]
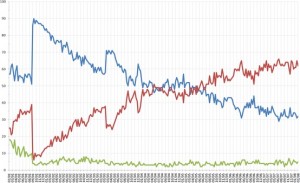
Yesterday, the President of IQS Research Shawn Herbig spent an hour on the radio discussing some of the intricacies involved […]
David J. Hand recently authored a short, concise book about statistics, aptly named Statistics, and in it he attempts to […]
McKinsey & Company recently released a report that claims that 30% of employers in the United States will drop their employee insurance coverage […]
A recent study carried out by our company and The Civil Rights Project for Jefferson County Public Schools came under […]




